- pdfOffice-例
- pdfOptimizer:フォント、画像、色空間の最適化のサポートが追加
- WidowとOrphanコンテンツサポートが追加
- pdfHTML:幅のパーセント値を持つインラインブロックのサポート
- pdf2Data:ASCII行記号区切り文字を使用したテーブルのサポートを追加
- pdfHTMLでのFlexboxサポート
- pdfHTML:非常に長い要素の処理
- Entrust Signing Automation Serviceを使用してPKCS#11を介して署名するためのIExternalSignature実装
- iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート5
- iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート4
- iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート3
- iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート2
- iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート1
- pdfHTMLでJavaScriptを評価する
- 大きなHTMLコンテンツをスケーリングして小さなPDFページサイズにレンダリングする
- 斜角、下線、およびはめ込みフォームフィールドの境界線スタイルのサポート
- pdfRender:WEBP形式のサポートが追加されました
- コアSVG:テキスト要素のfont-sizeプロパティのフォント相対単位のサポートが追加されました
- コアSVG:
要素をサポート - pdfHTML:オーバーフローラップ、ワードブレイクCSSプロパティのサポート
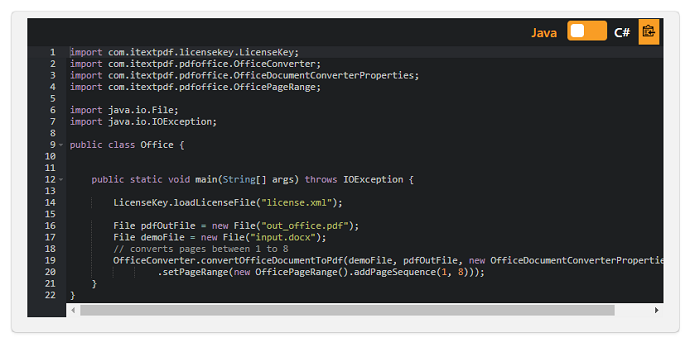
pdfOfficeは、WordまたはPowerPointファイルからPDFドキュメントを生成できるiText 7アドオンです(Excelは、間もなく登場します)。
現在サポートされているファイルの種類は、
.doc、.docx、.dotx、docm、.dotm、.dot、.ppt、.pptx、.potx、.pptm、.potm、.ppsx、.ppsm、.pot、および.ppsです 。
以下の例は、Word ドキュメント (.docx) を PDF に変換する方法を示しています。
pdfOptimizer:フォント、画像、色空間の最適化のサポートが追加
バックグラウンド:
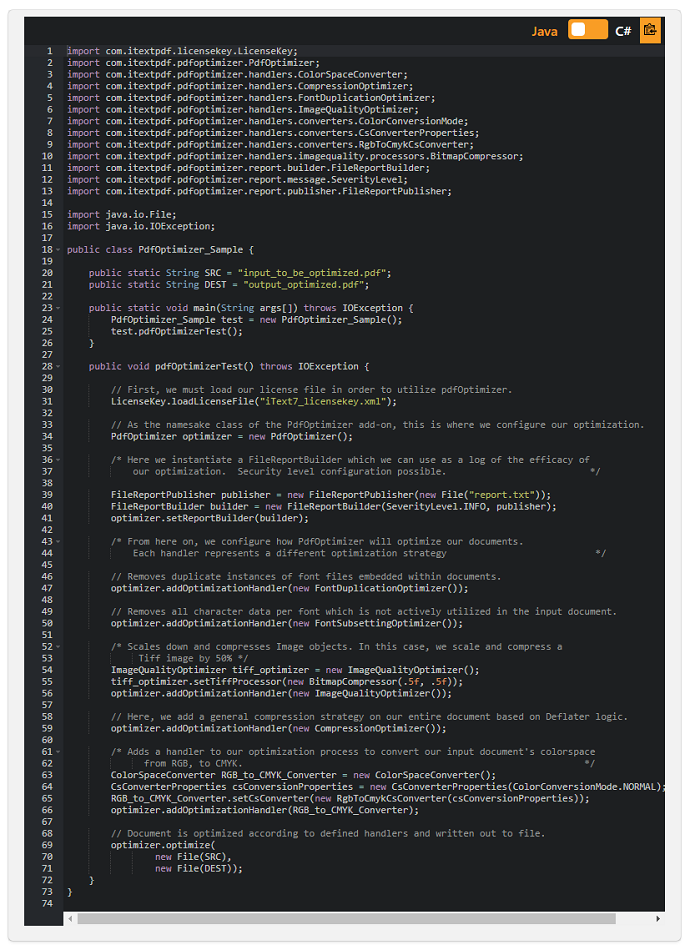
pdfOptimizerは、PDFドキュメントスペースにおけるiTextの最新かつ最大のイノベーションです。
特にドキュメント内の属性の圧縮と変更の領域内で、コアライブラリに広範な追加機能を提供します。
コードサンプル:
以下は、1.0.1安定版リリースの時点でpdfOptimizerの現在リリースされている各機能を示すフル機能のコードスニペットです。
このコードスニペットでは、次の機能について説明します。
- フォント複製の最適化:
- フォントファイル全体の重複インスタンスの削除、またはPDFドキュメント内のフォントファイルの重複埋め込みサブセットの削除を指します。
- フォントサブセットの最適化:
- 埋め込むフォントファイルのすべてのグリフデータではなく、実際にドキュメント内のテキストで使用されているグリフデータのみを埋め込むことができます。
- 画像スケーリングの制御と圧縮:
- ユーザーは、PDFドキュメントに埋め込まれた画像の解像度を縮小するだけでなく、 デフレーター圧縮アルゴリズムを適用してスペースをさらに節約することができます。
- 色空間変換:
- ユーザーがドキュメントの配色をRGBからCMYKに、またはその逆に転送できるようにします。
ただし、開発チームがこの安定版リリースに機能を追加し続けると、この例は大幅に拡張されます。
このコードスニペットの下には、各最適化ハンドラーの入力ドキュメントと出力ドキュメントがあり、視聴者はPdfOptimizerの有効性を直接確認できます。
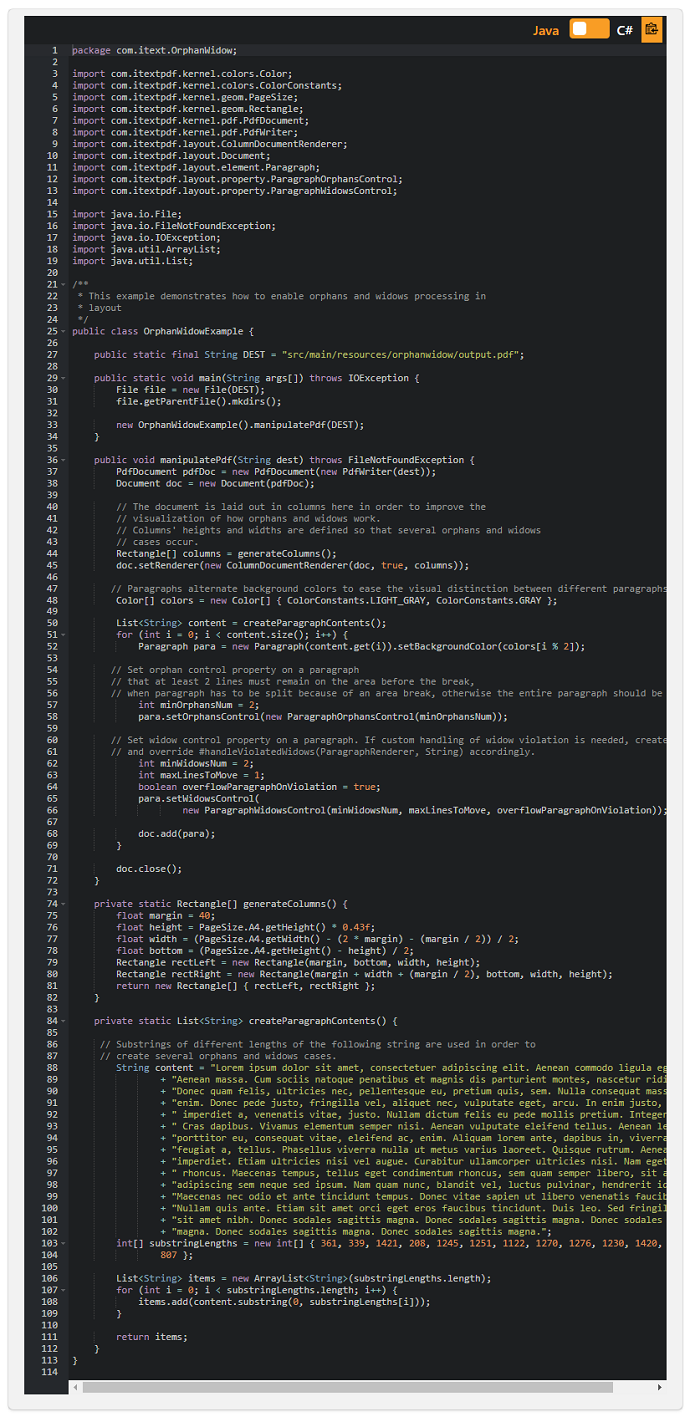
iText 7.1.11 では、ドキュメント ページでコンテンツが正確に表示されるように、 ウィドウコンテンツおよびオーファンコンテンツの制御のサポートが追加されました。
詳細
- Widowは、段落、列、またはページの下部に表示される単一の単語または単語の短いグループです。
- それらは、テキストの長いセクションが不均衡で乱雑に見えるだけでなく、ページの終わりに余計な空白を残しすぎる傾向があります。
- Orphanは同様の不要なストラグラーですが、これはページの上部に表示される単語を表します。
- Orphansは実際には前のページに属しています。 表示されているページが乱雑に見えるだけでなく、2つのページにまたがる読書の流れを壊してしまうからです。
Widow text

Orphan text

以下は、レイアウトでWidowとOrphanの処理を有効にする方法を示す例です。
pdfHTML:幅のパーセント値を持つインラインブロックのサポート
以前のバージョンのpdfHTMLには、特定の状況でspanやlabelタグタグの使用を完全にサポートしていなかったCSSのバグがありました 。 たとえば、 "display: inline-block; width: x%;"を利用する場合、 インラインボックスの幅が正しくレンダリングされず、 テキストが間にスペースなしで表示されていました。
pdfHTML 3.0.4のリリースにより、これらのタグのパーセンテージ値としての幅の使用が完全にサポートされるようになり display: inline-block;の使用は正しく機能します。
以下は、いくつかのサンプルHTMLをpdfHTML3.0.4および以前のバージョンで変換したときの結果の比較です。

pdfHTML 3.0.3:
これ(および以前のバージョンのpdfHTML)を使用すると、上記のHTMLが次のPDF出力に変換されます。

ご覧のとおり、指定されたラベルの幅は無視されました。
pdfHTML 3.0.4の場合:
この問題を解決するために、iText開発チームはこれらの要素とCSSプロパティを一緒に使用するためのサポートを追加しました。
この解像度は実際のHTMLからPDFへの変換方法には影響しないため、以下に示すのと同じ手順を引き続き使用します。
ただし、ご覧のとおり、このHTMLの例を結果のPDFで正しくレンダリングします。

pdf2Data:ASCII行記号区切り文字を使用したテーブルのサポートを追加
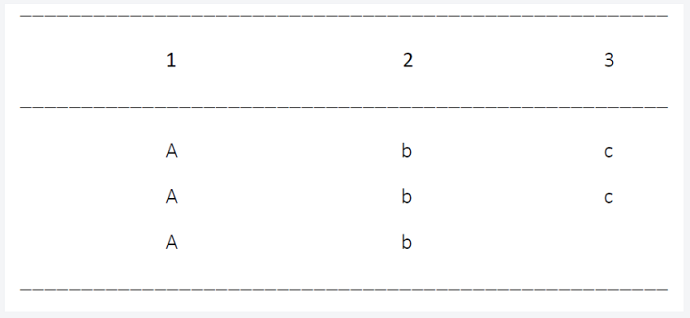
以前のバージョンでは、pdf2Dataは、ASCIIグラフィックを使用して描画された水平線を使用するテーブルを認識できませんでした。
ただし、pdf2Data バージョン2.1.11では、ASCII水平線の正確で完全な認識がサポートされています。
以下のスクリーンショットは、水平ASCII線を使用して描画されたテーブルを示しています。
結果のテンプレートは次のようになります。

同様に、output xmlは次のことを示しています。
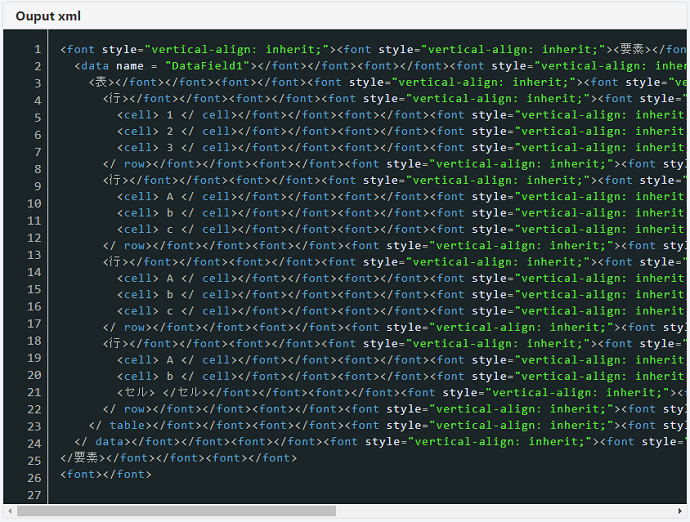
pdfHTML 3.0.4のリリースに伴い、CSSフレキシブルレイアウトボックスモジュールモジュールがサポートされるようになりました 。
バックグラウンド
一般にFlexboxとして知られているCSSフレキシブルボックスレイアウトは、CSS 3Webレイアウトモデルです。
現在、W3Cの候補推奨段階にありますが、数年前から存在しており、幅広いブラウザをサポートするシンプルで信頼性が高く、
高速なソリューションであるため、人気があることが証明されています。
フレックスレイアウトにより、コンテナ内のレスポンシブ要素を画面サイズに応じて自動的に配置できます。
Flexbox Layoutモジュールの前には、4つのレイアウトモードがありました。
- Block:Web ページのセクション
- Inline:テキスト用
- Table:2 次元テーブル データ
- Positioned:要素の明示的な位置
フレキシブルボックスレイアウトモジュールを使用すると、フロートやポジショニングを使用せずに、柔軟でレスポンシブなレイアウト構造を簡単に設計できます。 Parent要素(フレックスコンテナ)とChild要素(フレックスアイテム)のすべての異なる可能なプロパティなどの詳細については、 A Complete Guide to Flexbox を参照してください。 履歴、デモ、パターン、ブラウザサポートチャートなど、役立つリソースもたくさんあります。
pdfHTML 3.0.4では、flexboxフレームワークの初期サポートが追加されました。 すべてのフレックスボックスプロパティのサポートはまだ包括的ではありませんが、すでに多くのユースケースを処理できます。
リマインダー
以下のHTMLコードをPDFに変換するために必要なことは、Javaまたは.NETのHtmlConverterクラスのメソッドの1つを実行することだけです。

例
次の例では、非常に一般的なユースケースとして次のHTMLコードを使用します。
つまり、ページの全幅に拡張された2列のレイアウトを作成します。
これらのスタイルは、フレックスボックス関連の動作を定義します。
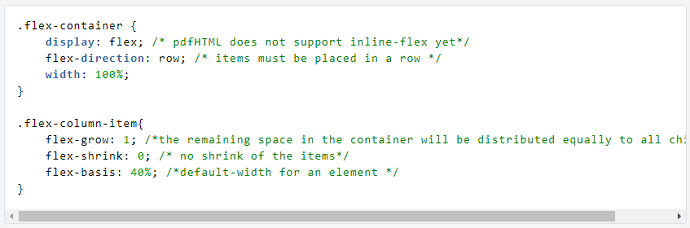
ご覧のとおり、フレックス列は、幅に関係なく、ページの全幅に伸びます。

Justify-contentプロパティ
初期幅(この場合は40%)を維持する必要がある場合があります。
その場合、それらの位置を指定することもできます。 これは justify-content Propertyを使用して行うことができます。
これにより、主軸に沿った配置が定義されます。行のすべての flex アイテムが柔軟でない場合、 または柔軟であるが最大サイズに達した場合に、余分な空き領域を分散するのに役立ちます。
pdfHTML 3.0.4は、次の値をサポートしています。
start、end、flex-start、flex-end、left、right、center。
これを行うには、スタイルを調整する必要があります。
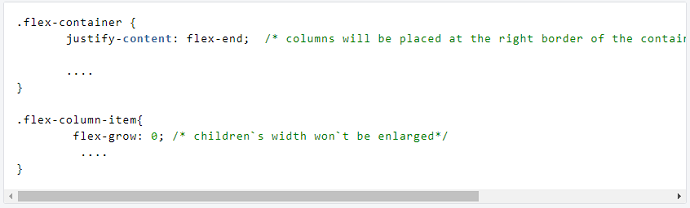
その結果、ページの右側の境界に2つの列が配置されました。

ネストされたサブ要素が多数ある段落を処理する場合、iTextは、 中間レンダラーをレイアウトした後に特定のParent linksをクリーンアップしないことにより、最適に動作しませんでした。 その結果、iTextは変換中に予想よりも多くのメモリを消費します。
7.1.15リリースでは、メモリリークの発生を防ぐために、コアレイアウトモジュールを最適化することでこの問題を修正しました。
以下のサンプルコードとリソースを使用して、問題をテストできます。
古いリリースでサンプルを実行すると、約600〜700MBのメモリが使用されてしまいます。これを最新バージョンで実行した場合のわずか100MBのメモリになります。
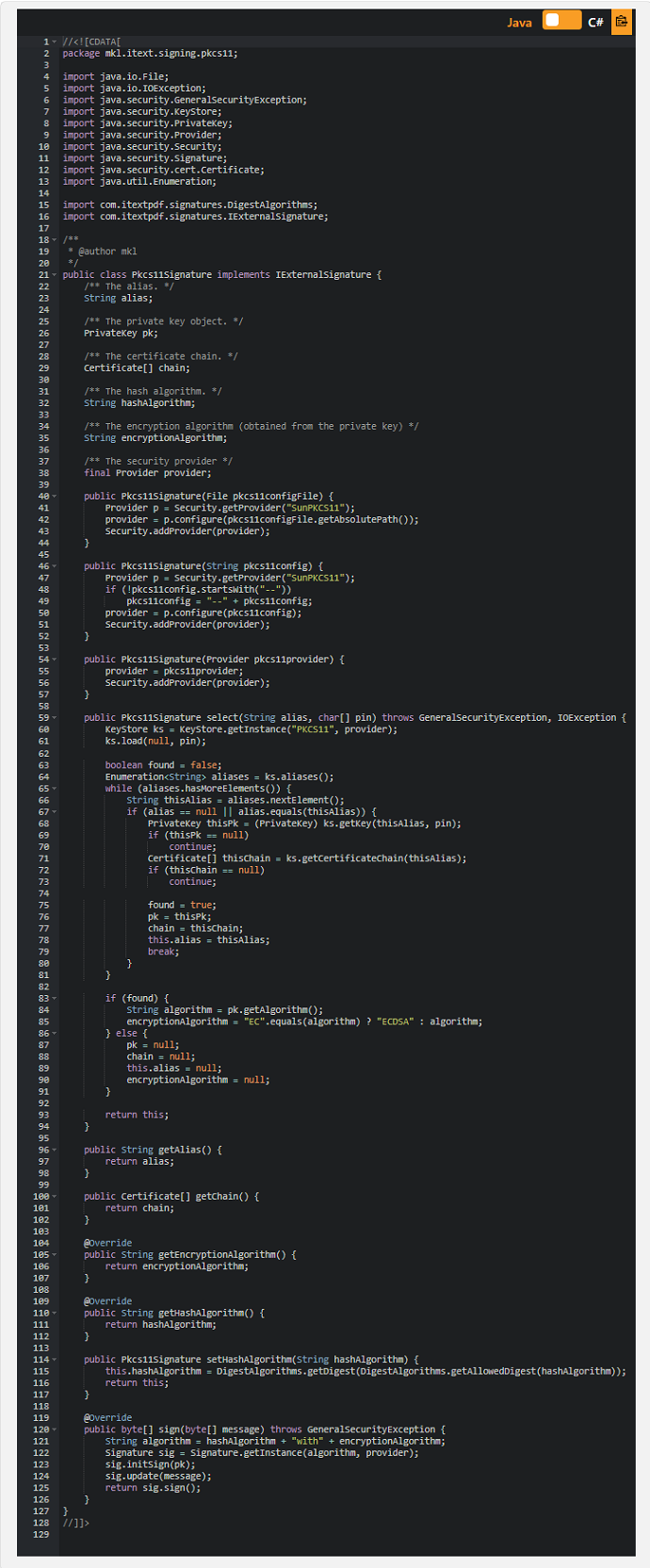
Entrust Signing Automation Serviceを使用してPKCS#11を介して署名するためのIExternalSignature実装
この例は、PDFドキュメントのPKCS#11署名にiTextとEntrust Signing AutomationServiceを使用する方法を示すために作成されました。 iText統合のプロセスは、Entrustが提供するマニュアルで説明されていますが、ここでは、この例に関連する基本について説明します。
Entrust SASユーザーガイドの指示に従って、SAS PKCS#11ドライバーがWindowsの
C:¥Program Files¥Entrust¥SigningAutomationClient¥P11SigningClient64.dllなどにインストールされます。
参考までに、Linuxでのセットアップは完全に類似しており、P11SigningClient64.dllへのパスをlibp11signingclient64.soへのパスに置き換えるだけで十分です。
結果として、PKCS#11の構成とインスタンス化は次のようになります。
この例では、Javaと.NETでのIExternalSignatureの実装が大きく異なることに注意してください。
Java実装は、Java JCA / JCE暗号化アーキテクチャに十分に統合されているJavaSun PKCS#11プロバイダーに基づいて構築されています。
構成ファイルのドキュメントの詳細については、
https://docs.oracle.com/javase/8/docs/technotes/guides/security/p11guide.html#Configを参照してください。
一方、.NET実装は、 NuGet(https://www.nuget.org/packages/Pkcs11Interop/)を介して取得できるPkcs11Interop パッケージに基づいて構築されています。 これは「アンマネージPKCS#11ライブラリのマネージ.NETラッパー」であるため、公式の.NET暗号アーキテクチャの一部ではありません。 これは、Apacheライセンスバージョン2.0の条件の下で利用できます。https://pkcs11interop.net/を参照してください。
iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート5
この例は、 「iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する」という記事のために作成され、 署名用のIExternalSignatureの代わりにIExternalSignatureContainerの実装を示しています。 IExternalSignatureが最も簡単な方法ですが、PdfPKCS7クラスがサポートしていないためいくつかの欠点があります。 RSASSA-PSSの使用法、およびECDSA署名の場合、署名アルゴリズムOIDとして間違ったOIDを使用します。
これらの問題を回避するために、BouncyCastle機能のみを使用して完全なCMS署名コンテナを自分で構築できます。
.NETの場合、AwsKmsSignatureContainerクラスはBouncyCastleを使用してJavaバージョンと同じように埋め込むCMS署名コンテナーを構築しますが、 .NET BouncyCastleAPIには特定の違いがあります。 特に、実際の署名にContentSignerのインスタンスを使用するのではなく、ISignatureFactoryのインスタンスを使用します。 そのインターフェースは、関数内でJavaのContentSignerと同等のIStreamCalculatorインスタンスのファクトリを表します。 これらのインターフェースの実装は、.NETの例ではAwsKmsSignatureFactoryとAwsKmsStreamCalculatorです。
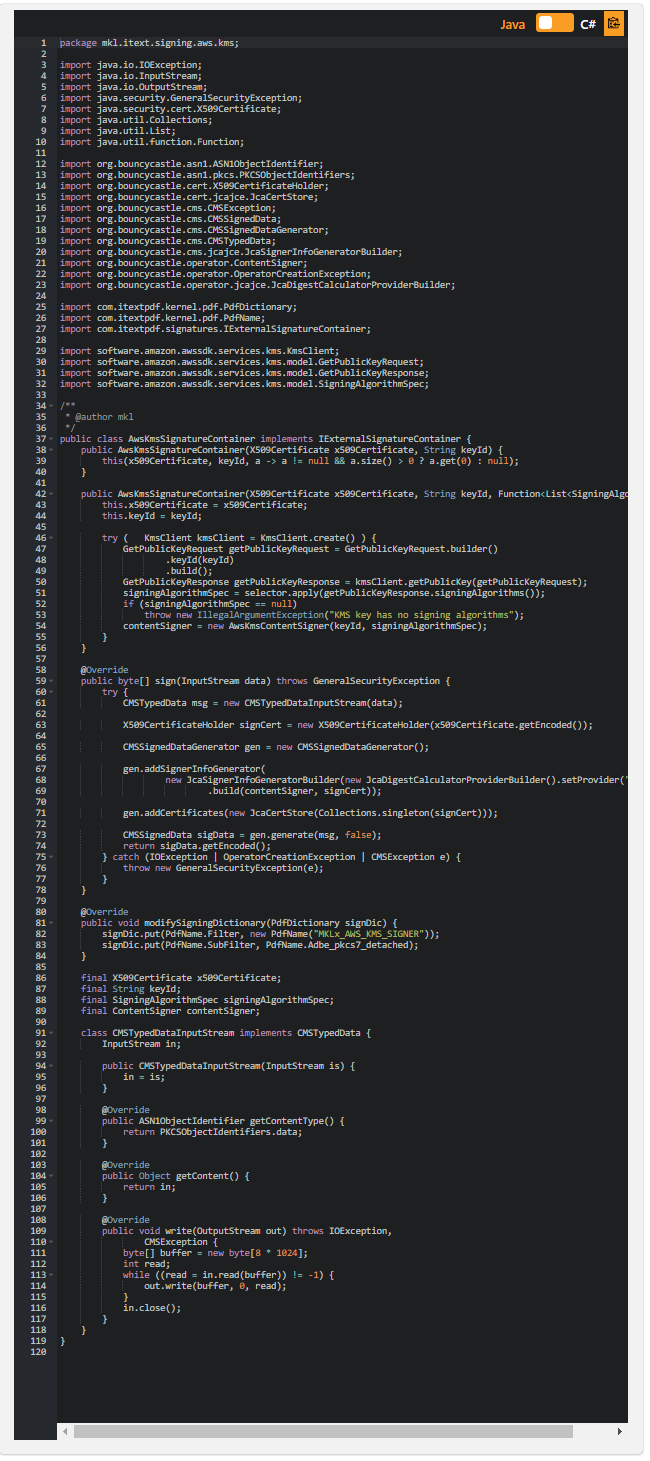
注:この記事では、〜/ .aws / credentialsファイルのデフォルトセクションにクレデンシャルを保存し、 〜/ .aws / configファイルのデフォルトセクションにリージョンを保存していることを前提としています。 それ以外の場合は、この記事用に記述されたコード例でKmsClientのインスタンス化または初期化を調整する必要があります。 この記事に関連する他の例については、Using iText 7 and AWS KMS to digitally sign a PDF documentの他のPartを参照してください。
iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート4
この例は、 「iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する」という記事のために作成され、 AWSKMSキーペアを使用してiTextでPDFに署名する方法を示しています。
AWS KMS署名キーペアにエイリアスSigningExamples-ECC_NIST_P256が あり、実際にECC_NIST_P256キーペアであるとするとAwsKmsSignature、 パート3のコードを使用して次のようなPDFに署名できます。
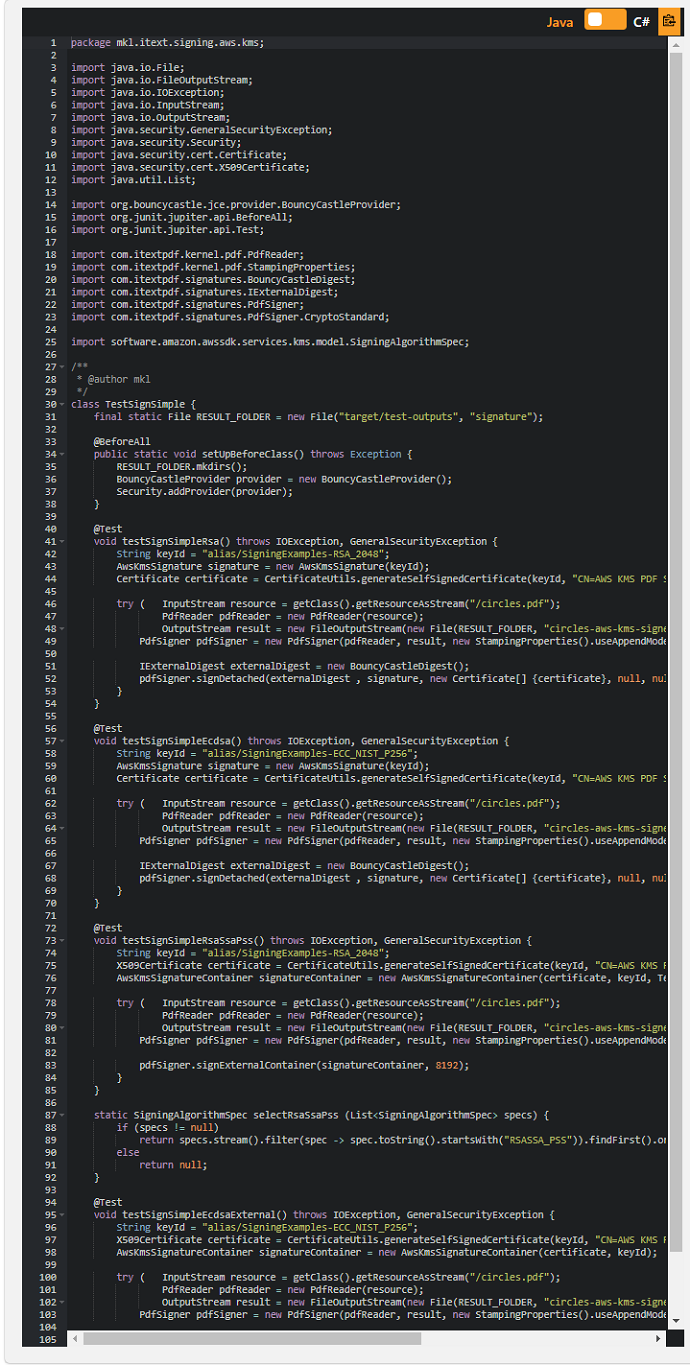
注:この記事では、〜/ .aws / credentialsファイルのデフォルトセクションにクレデンシャルを保存し、 〜/ .aws / configファイルのデフォルトセクションにリージョンを保存していることを前提としています。 それ以外の場合は、この記事用に記述されたコード例でKmsClientのインスタンス化または初期化を調整する必要があります。 この記事に関連する他の例については、Using iText 7 and AWS KMS to digitally sign a PDF documentの他のPartを参照してください。
iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート3
この例は、 「iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する」という記事のために作成され、 AWSKMSキーペアを使用してPDFに署名するためのiText IExternalSignature インターフェイスの実装を示し ています。
コンストラクターで、問題のキーに使用できる署名アルゴリズムを選択します。 ただし、記事で説明されているように、最初のアルゴリズムを使用するのではなく、特定のハッシュアルゴリズムの使用を強制することもできます。
この例では、getHashAlgorithmとgetEncryptionAlgorithmが署名アルゴリズムのそれぞれの部分の名前を返し、signは単に署名を作成します。
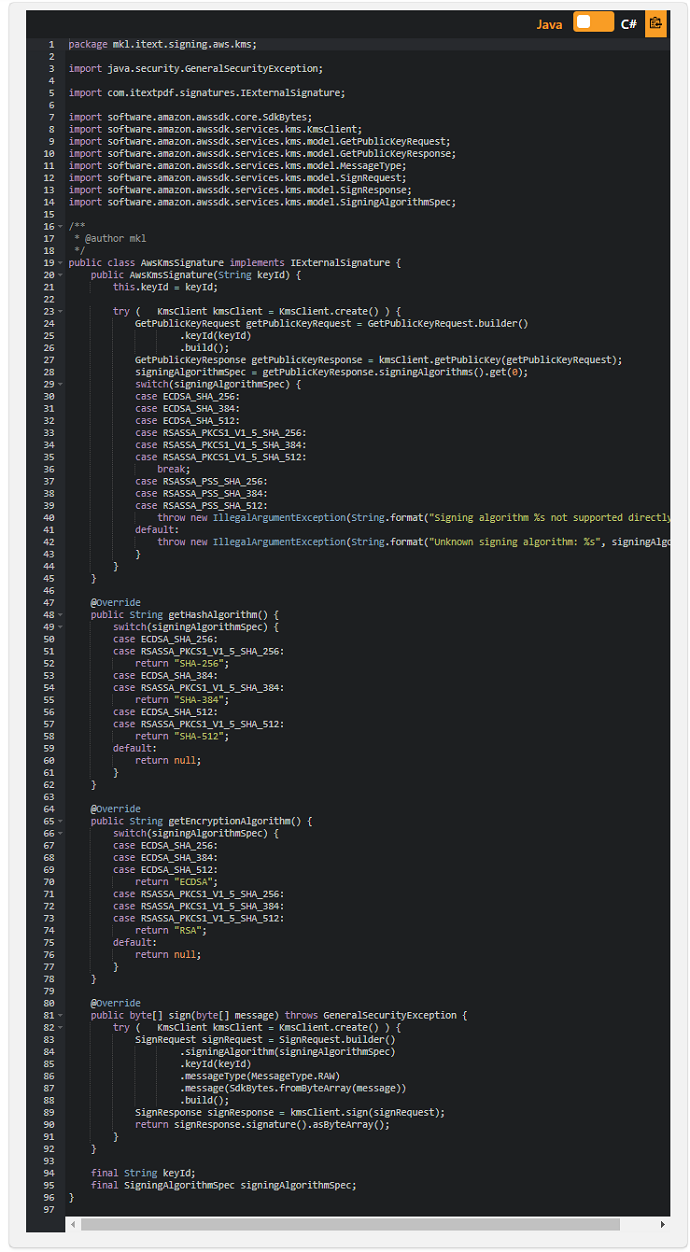
注:この記事では、〜/ .aws / credentialsファイルのデフォルトセクションにクレデンシャルを保存し、 〜/ .aws / configファイルのデフォルトセクションにリージョンを保存していることを前提としています。 それ以外の場合は、この記事用に記述されたコード例でKmsClientのインスタンス化または初期化を調整する必要があります。 この記事に関連する他の例については、Using iText 7 and AWS KMS to digitally sign a PDF documentの他のPartを参照してください。
iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート2
この例は、 「iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する」という記事のために作成され、 BouncyCastleインターフェースContentSignerの実装を示しています。
この例はJavaのみです。これは、パート1の.NETバージョンのCertificateUtilsが証明書の生成にBouncyCastleを使用せず、 代わりに.NETX509SignatureGeneratorを使用しているためです。
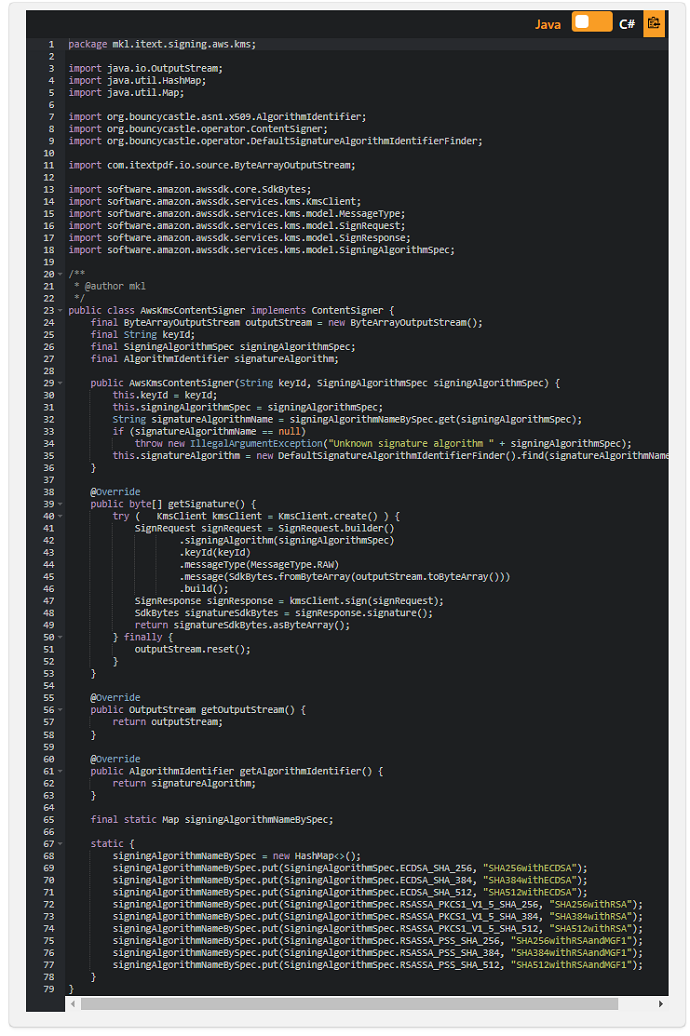
注:この記事では、〜/ .aws / credentialsファイルのデフォルトセクションにクレデンシャルを保存し、 〜/ .aws / configファイルのデフォルトセクションにリージョンを保存していることを前提としています。 それ以外の場合は、この記事用に記述されたコード例でKmsClientのインスタンス化または初期化を調整する必要があります。 この記事に関連する他の例については、Using iText 7 and AWS KMS to digitally sign a PDF documentの他のPartを参照してください。
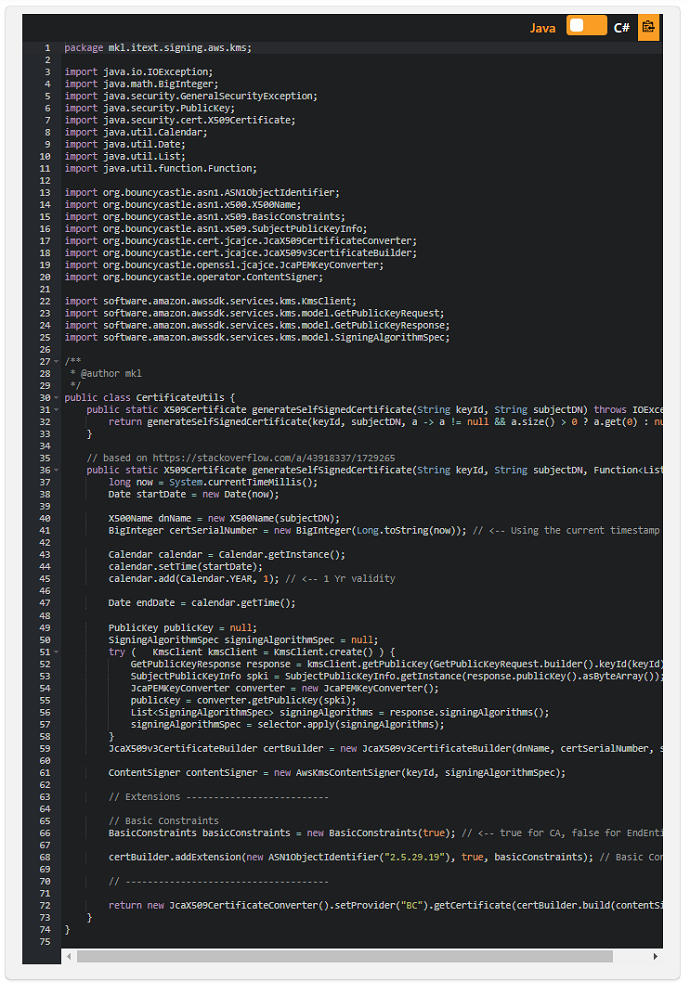
iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する:パート1
この例は、 「iText7とAWSKMSを使用してPDFドキュメントにデジタル署名する」という記事のために作成され、 AWSKMSキーペアで使用できるテスト目的の自己署名証明書を生成する方法を示しています。
ただし、本番環境では、通常、信頼できる認証局(CA)によって署名された証明書を使用することをお勧めします。 これは、この例に示されているのと同様の方法で、AWS KMS公開鍵の証明書要求を作成して署名し、それを選択したCAに送信し、 それらから使用する証明書を取得することで実行できます。
pdfHTMLはJavaScriptを評価しませんが、ブラウザエンジンを使用してHTML+CSS+JavaScriptを前処理することで、この問題を解決できます。 このようなブラウザエンジンの例としては、WebKit(Chrome、Safari)、Gecko(Firefox)などがあります。 この例では、ヘッドレスChromeと組み合わせて、ブラウザーの自動化にSeleniumWebDriverを使用しています。
入力HTMLファイルは非常に単純です。
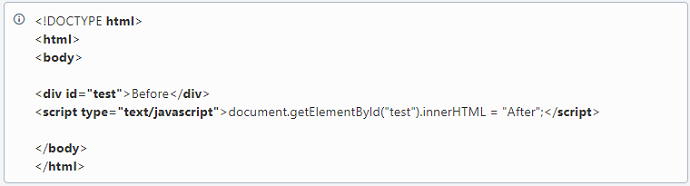
JavaScriptの評価前は、このHTMLは単に「前」と表示されますが、JavaScriptの評価後は「後」と表示されます。
それでは、ブラウザエンジンをミックスに追加する前に、出力を見てみましょう。
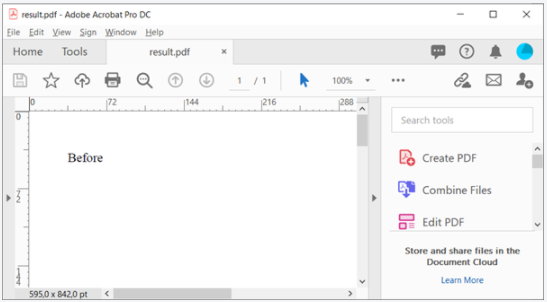
予想どおり、JavaScriptは評価されていません。
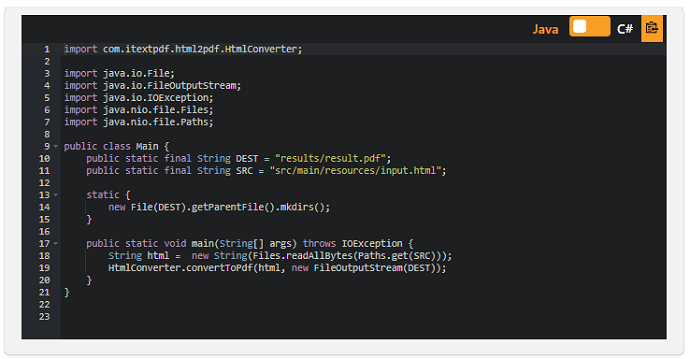
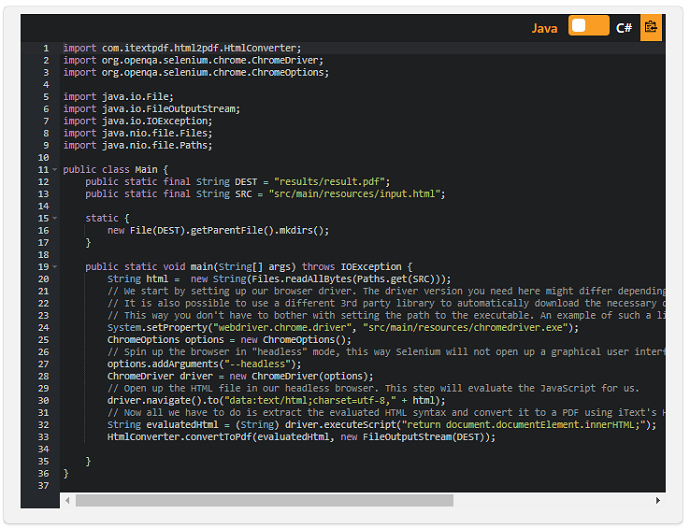
それでは、ヘッドレスブラウザを使用してもう一度試してみましょう。 まず、ヘッドレスブラウザを起動する機能を備えたライブラリを含める必要があります。 この場合、.NETとJavaの両方で使用できるため、Seleniumを選択しています。
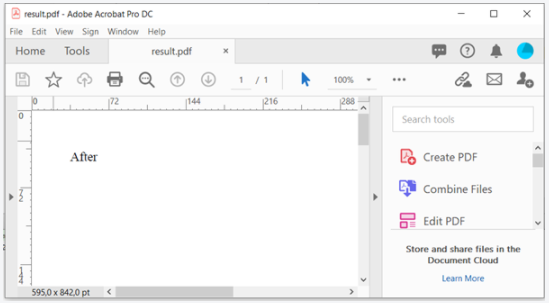
ご覧のとおり、今回はJavaScriptが正しく評価されました。 そして、出力はJavaScriptが実行された後のHTMLの状態を反映しています。
注意:JavaScriptは、HTMLがロードされたときに実行される場合にのみ評価できます。 スクリプトがドキュメントの読み込みではなくアクション(ボタンを押すなど)にバインドされている場合、 スクリプトはブラウザエンジンによって処理されません。 より複雑なドキュメントの場合、JSがロードされて実行されるのを待つ必要があるかもしれません。 これは、WebDriverWaitsを利用して行うことができます。
大きなHTMLコンテンツをスケーリングして小さなPDFページサイズにレンダリングする
PDFのデフォルトのページサイズよりも大きいHTMLコンテンツを変換する必要がある場合がよくあります。
これにより、生成されたPDFファイルのコンテンツが重複したり、ページからコンテンツがレンダリングされたりします。
最も簡単な解決策は、PDFページサイズを実際にHTMLコンテンツに適合するサイズに変更することです。
ただし、特定のページサイズ(A4やレターなど)のPDFを生成することをお勧めします。
フォントや余白のサイズを変更することも出来ますが、もちろんこれが常に可能であるとは限りません。
会社の特定のページサイズだけでなく、彼らのブランディングガイドラインが特定のフォント、
ページ余白などを使用しなくてはいけない状況を考えてみましょう。
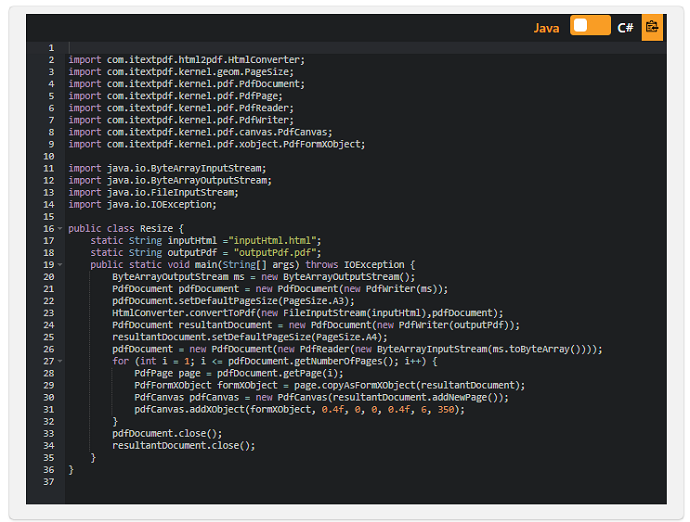
より良い解決策は、HTMLコンテンツを必要なページサイズに再スケーリングすることです。これを行うには、次の手順で実行できます。
- HTMLを、少なくともHTMLコンテンツを含めるのに十分な大きさのデフォルトのページサイズに変換します。
- ページを繰り返し処理し、各ページをformXObjectとしてコピーします。
- 各ページ formXObject について、0.4 係数 (または適切と思われるもの) でスケーリングします。
- 必要なページサイズで、結果のドキュメントにコンテンツを追加します。このプロセスを示す例を以下に示します。
斜角、下線、およびはめ込みフォームフィールドの境界線スタイルのサポート
iText 7 Core 7.1.14では、以前は欠落していたPDFフォームフィールドにいくつかの境界線スタイルを実装しました。 問題のスタイルは、斜角、下線、はめ込みの境界線です。
以下に、新しくサポートされた3つの境界線スタイルすべてを示すサンプルコードスニペットと、 このコードスニペットを実行したときに期待できる出力例を示します。
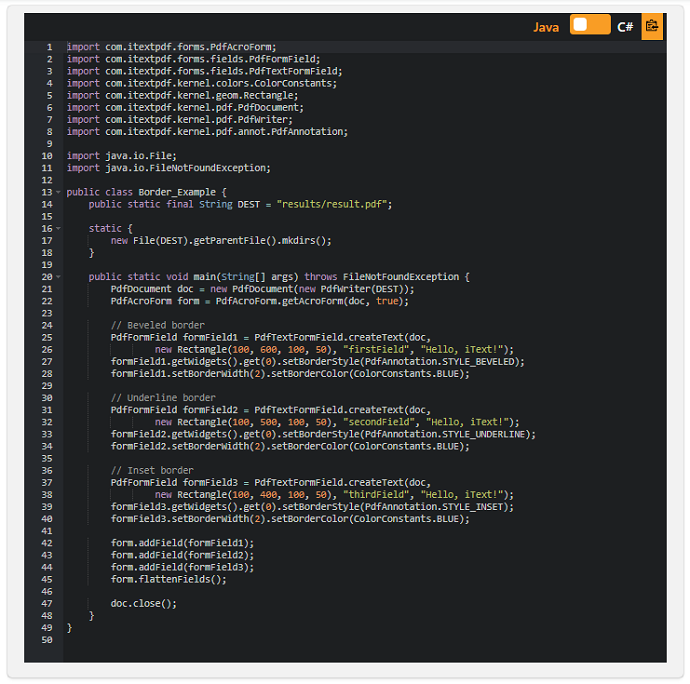
Output: こちらからPDFが確認できます。
iText 7.1.14リリースでは、pdfRender1.0.3にWEBP画像形式のサポートが追加されました。 これは、非可逆圧縮と可逆圧縮の両方を採用する最新の画像形式であり、通常、同等の品質設定でJPEGまたはPNGよりも小さい画像を生成します。
実際のpdfRenderライブラリには、WEBP画像を処理できるようになったという事実を除けば、それほど大きな変更はありません。 これを実行するコードは、過去にpdfRenderを実験または操作したことのあるiTextユーザーにもよく知られているはずです。
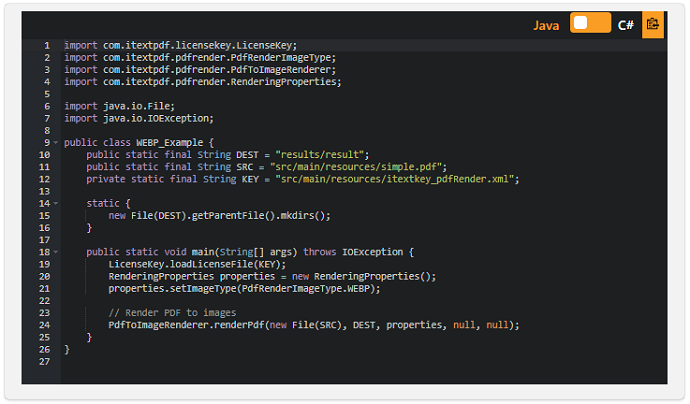
現在、pdfRender .NETライブラリは利用できませんが、複数のプログラミング言語(C#for .NETを含む)
で動作するCLI(コマンドラインインターフェイス)バージョンはあります。
pdfRender CLIの詳細については、
FAQを参照してください。
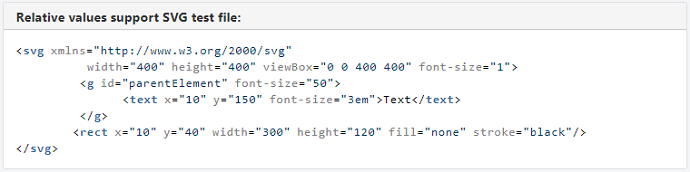
コアSVG:テキスト要素のfont-sizeプロパティのフォント相対単位のサポートが追加されました
以前のiText7 Coreバージョンでは、SVGのテキスト要素のfont-size属性が特定のケースで正しく計算されていませんでした。
これは、フォントサイズに相対的な長さの単位(em、remなど)が使用されている場合、iTextが代わりにデフォルトの動作を使用するために発生しました。
ただし、iText 7 Coreバージョン7.1.14では、これらの値の正しいレンダリングがサポートされています。
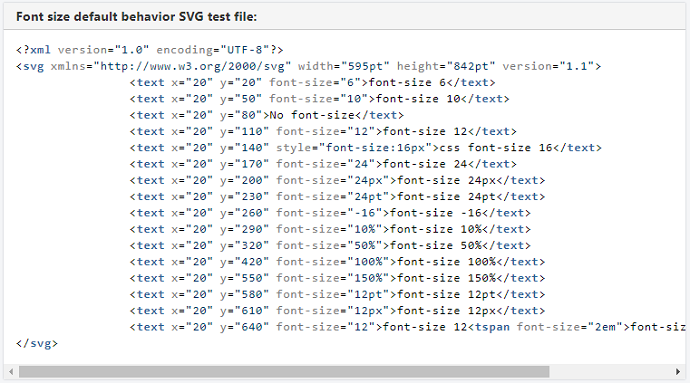
さらに、従来のデフォルトの動作は、関連するParentがないフォントサイズ要素の100%および1emの単位に適用されます。
SVGフォントサイズのドキュメントの詳細については、次のリンクを参照してください。
https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/font-size
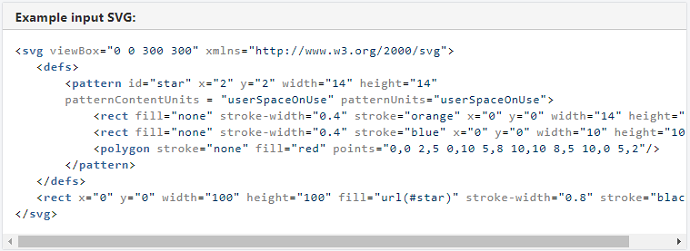
入力SVGの例:
フォントサイズのデフォルトの動作SVGテストファイル:
SVGからPDFを生成するためのiText7コアコードは同じままです:
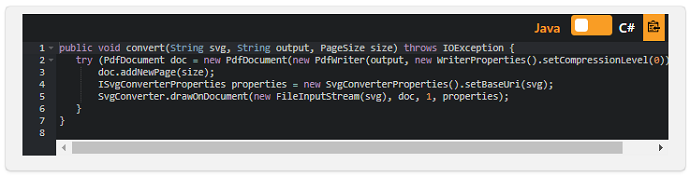
iText7.1.14とpdfHTML3.0.3で、SVGの
iText 7 CoreのSVGモジュールの
SVG
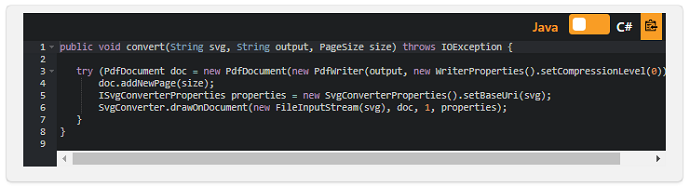
SVGからPDFを生成するためのiText7コアコードは同じままです。
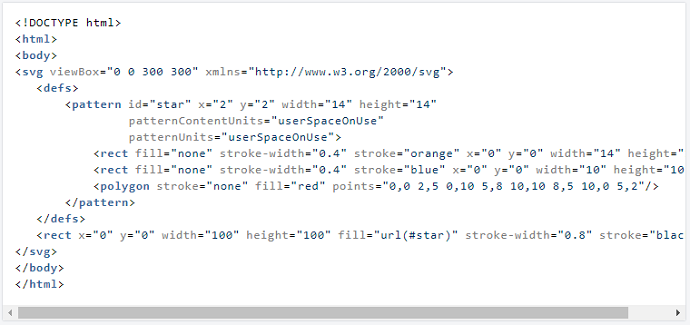
入力HTMLの例:
HTMLからPDFを生成するためのpdfHTMLコードは同じままです。

pdfHTML:オーバーフローラップ、ワードブレイクCSSプロパティのサポート
バックグラウンド:
iText Core7.1.14およびpdfHTML3.0.3に付属するさまざまな機能の追加とバグ修正の中に、
overflow-wrapおよびword-break CSSプロパティのサポートが追加されています。
どちらのプロパティも、HTMLのテキスト要素内に改行を挿入するかどうか、および挿入する方法を決定するのに役立ちます。
オーバーフローラップ
バックグラウンド:
以前は「ワードラップ」と呼ばれていたオーバーフローラップは、含まれている境界をオーバーフローするテキストを防ぐために、
ブラウザが単語間の行を分割できるかどうかを指定するために使用されるCSSプロパティです。
次のセクションでは、overflow-wrapのさまざまな機能を示し、テスト用にHTMLコードスニペット、Java / C#コードサンプル、および出力PDFドキュメントを提供します。
機能のデモンストレーション:
オーバーフロー・ラップ:normal; 設定は、改行はnatural moments(2つの単語の間にスペースがある場合)にのみ発生することを表明します。
そのため、以下のような長い単語は、その範囲を超えてオーバーフローします。

オーバーフローラップ:break-word; 設定は、行内に許容可能なブレークポイントがあるかどうかに関係なく、オーバーフローした単語をブレークします。

オーバーフロー・ラップ:anywhere; 設定では、行内に許容できる区切り点がない場合に、オーバーフローした単語内で改行を許可します。

オーバーフローラップ:break-all; ブレークワードの機能を拡張して、テキスト領域のマージンをオーバーフローする文字の前に改行を挿入します。

オーバーフローラップ:hyphensブレークオールの機能が含まれていますが、改行がある場合は 常にハイフンを挿入します。

再現可能な例:
以下は、上記の例のソースHTMLです。
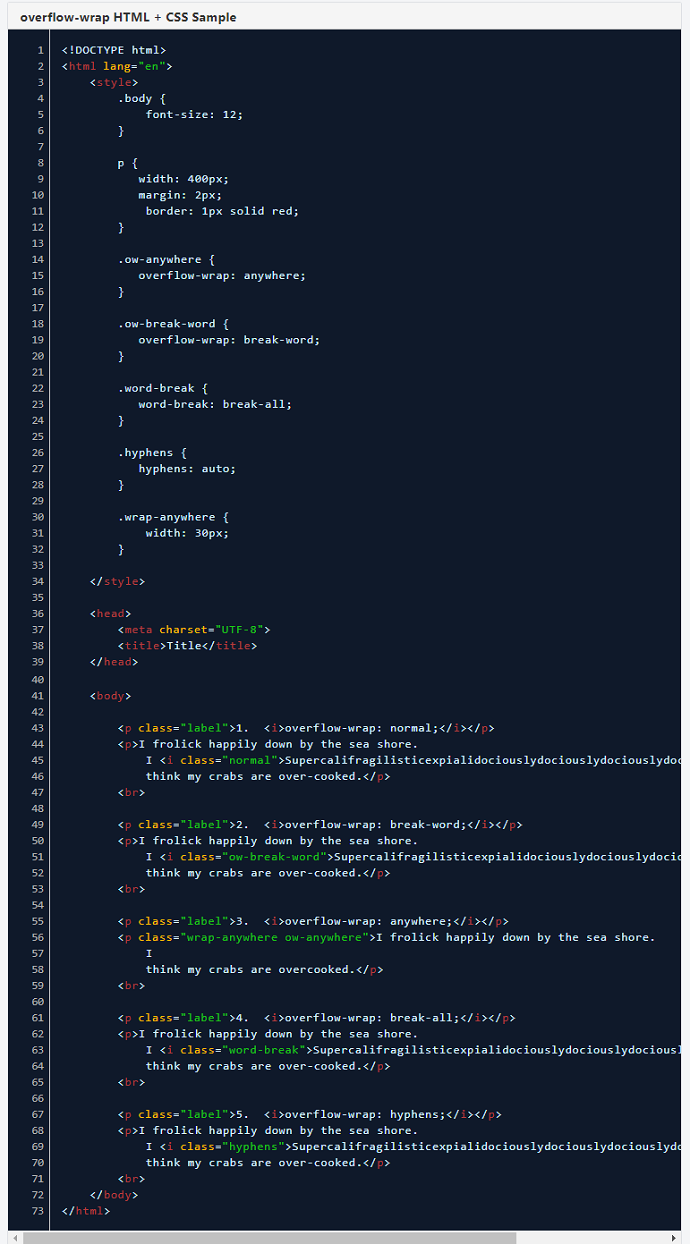
以下は、上記のHTMLスニペットをPDFに変換するためのコードスニペットです。
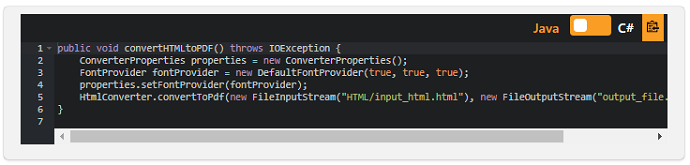
以下は、結果のPDFドキュメントです。

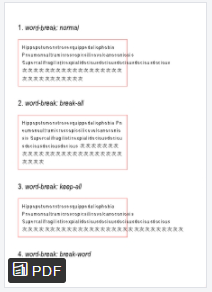
ワードブレイク
バックグラウンド:
word-breakプロパティは、テキスト要素内に改行を挿入する方法を指定するために使用されます。
次のセクションでは、overflow-wrap のさまざまな機能を示し、HTML スニペット、Java/C# コード サンプル、
および pdfHTML で生成された出力 PDF ドキュメントを提供します。
機能のデモンストレーション:
ワードブレイク:normal; プロパティは、標準の改行ルールを保持します。

ワードブレイク:break-all; プロパティは、その領域をオーバーフローする文字の前に改行を挿入します。

ワードブレイク:keep-all;通常の単語区切り設定を、CJK(中国語、日本語、韓国語)文字を含むすべてのテキストに適用します 。

ワードブレイク:break-word; プロパティには、オーバーフローラップanywhere; functionality;と同じ機能があります。

再現可能な例:
以下は、上記の例のソースHTMLです。
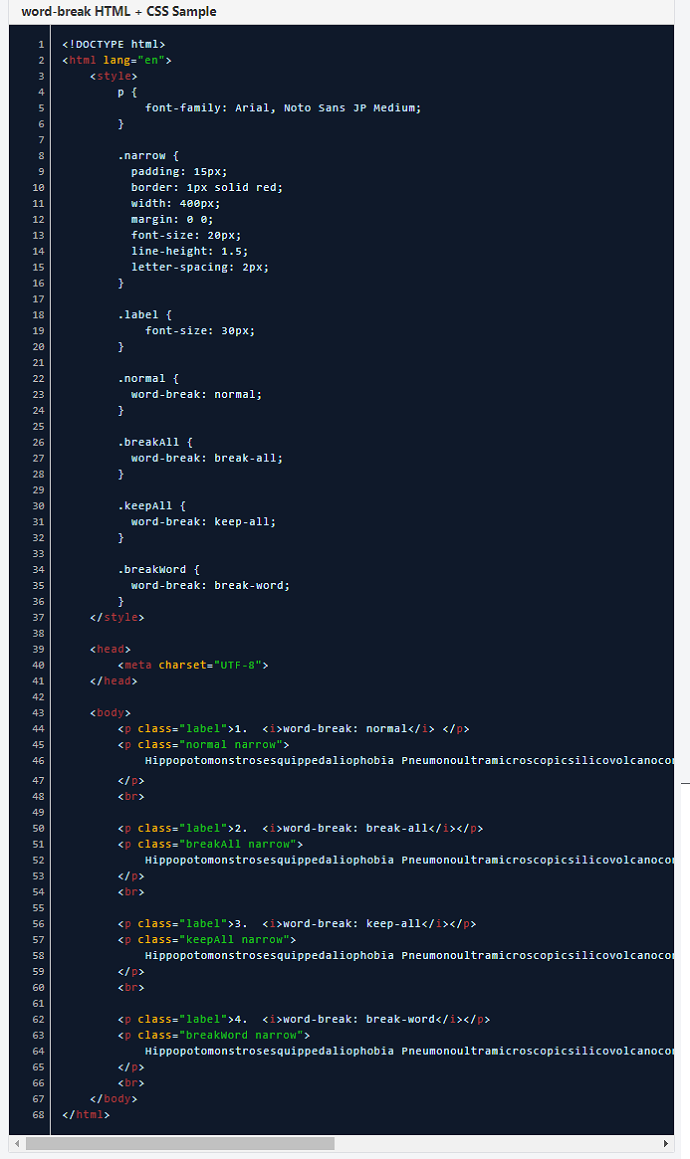
以下は、上記のHTMLスニペットをPDFに変換するためのコードスニペットです。 HTMLでアジアの文字を正しくレンダリングするために、NotoSansJP-mediumフォントを埋め込みます。 (ダウンロード)
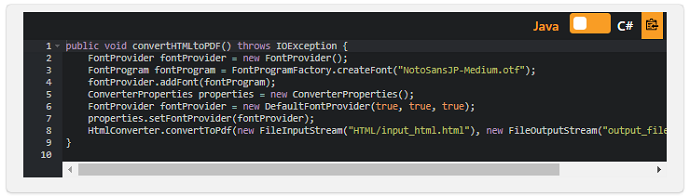
以下は出力されたPDFです。